Abstract
Hard constraints in reinforcement learning (RL) often degrade policy performance. Lagrangian methods offer a way to blend objectives with constraints, but require intricate reward engineering and parameter tuning. In this work, we extend recent advances that connect Hamilton-Jacobi-Bellman (HJB) equations with RL to propose two novel value functions for dual-objective satisfaction. Namely, we address: 1) the Reach-Always-Avoid (RAA) problem – of achieving distinct reward and penalty thresholds – and 2) the Reach-Reach (RR) problem – of achieving thresholds of two distinct rewards. In contrast with temporal logic approaches, which typically involve representing an automaton, we derive explicit, tractable Bellman forms in this context via decomposition. Specifically, we prove that the RAA and RR problems may be rewritten as compositions of previously studied HJ-RL problems. We leverage our analysis to propose a variation of Proximal Policy Optimization (DOHJ-PPO), and demonstrate that it produces distinct behaviors from previous approaches, out-competing a number of baselines in success, safety and speed across a range of tasks for safe-arrival and multi-target achievement.
Dual-Objective Value Functions
Given a state \(s\), an action-sequence \(\alpha := (a_1, a_2, ... ) \), and time horizon \(t := (t_1, t_2, ... ) \), we propose two novel Values for optimal dual-satisfaction of a trajectory \( s_t^\alpha \).
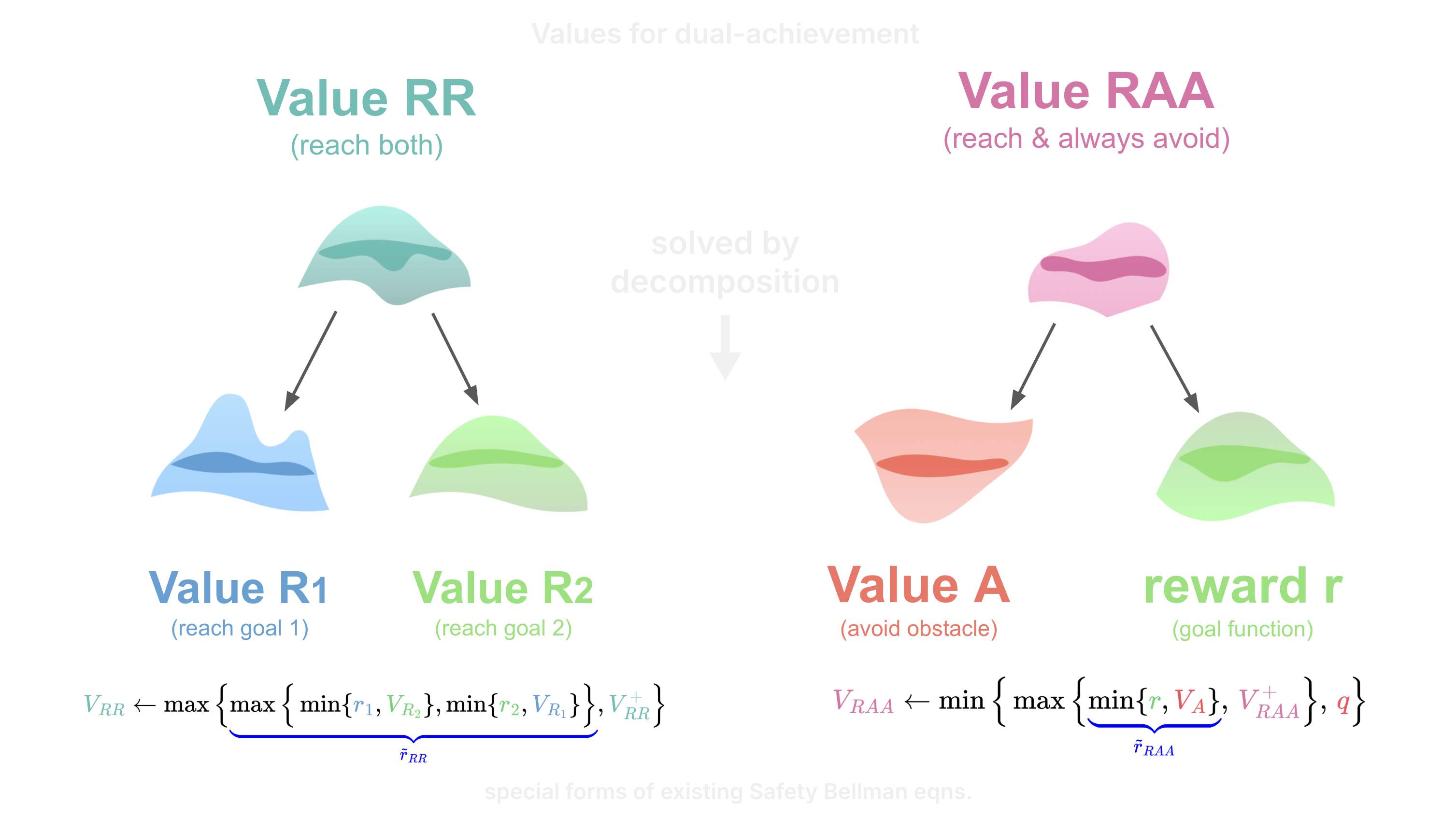
To maximize two rewards \(\textcolor{#58A0D6}{r_1}\) and \(\textcolor{#56D273}{r_2}\), let the Reach-Reach Value \( V_{\textcolor{#59BFB5}{\textrm{RR}}} \) be defined,
Hence, for a given state, if \(V_{\textcolor{#59BFB5}{\textrm{RR}}} \ge 0 \) there must be actions to achieve \(\textcolor{#58A0D6}{r_1} \ge 0 \) and \(\textcolor{#56D273}{r_2} \ge 0 \) at some future times, i.e. we can reach two targets.
To maximize a reward \(\textcolor{#56D273}{r}\) and a negative penalty \(\textcolor{#F54D59}{q}\), let the Reach-Always-Avoid Value \( V_{\textcolor{#E070A6}{\textrm{RAA}}} \) be defined,
Similarly, for a given state, if \(V_{\textcolor{#E070A6}{\textrm{RAA}}} \ge 0 \) there must be actions to achieve \(\textcolor{#56D273}{r} \ge 0 \) at some future time and satisfy \(\textcolor{#F54D59}{q} \ge 0 \) for all times, i.e. we can reach a target and avoid obstacles forever.
Note, these Values are defined by max/min-over-time objectives in HJB fashion [Mitchell 2005] to ensure dual-achievment, rather than canonical discounted-sum objectives. This yields behaviors that act with respect to outlying (best/worst) future performance, rather than ~average future performance.
Deriving the RR & RAA Bellman eqns via Decomposition
To solve these Values, one may recognize their inherent structure, namely how the maximum over actions commutes over the minimum of dual objectives.
We prove that the RR Value is equivalent to a Reach Value [Mitchell 2005] with a special reward \(\textcolor{blue}{\tilde{r}_{\textrm{RR}}}\) defined by the Reach Values of the rewards independently \(V_{\textcolor{#58A0D6}{\textrm{R}_1}}\) and \(V_{\textcolor{#56D273}{\textrm{R}_2}}\). Hence, the corresponding Safety Bellman eqn. [Fisac 2019],
can be used to solve the Value with RL.
Similarly, we prove that the RAA Value is equivalent to a Reach-Avoid Value [Fisac 2015] with a special reward \(\textcolor{blue}{\tilde{r}_{\textrm{RAA}}}\) defined by the Avoid Value of the negative penalty independently \(V_{\textcolor{#F54D59}{\textrm{A}}}\). Moreover, the corresponding Reach-Avoid Safety Bellman eqn. [Hsu 2021],
can be used to solve the Value with RL.
In summary, the Values of interest are equivalent to special cases of well-studied HJ-RL problems with layered solutions, and thus can be solved by simple extensions of existing algorithms. See the paper for details about deriving the corresponding optimal policy via a minimal state-augmentation.
DOHJ-PPO
Based on the decompositional results, we propose DOHJ-PPO, a derivative of PPO with only the following modifications: (1.) a critic is used for each de/composed Value, and all are trained with the Stochastic Safety Bellman eqn GAE [So 2024] (2.) all Values are learned concurrently by bootstrapping (3.) resets are coupled by initializing decompositions from the composed rollout.
We test our algorithm in four envs and eight tasks against ten baselines, including augmented-lagrangian algs., adapted single-objective HJ-RL algs., and STL-RL algs.
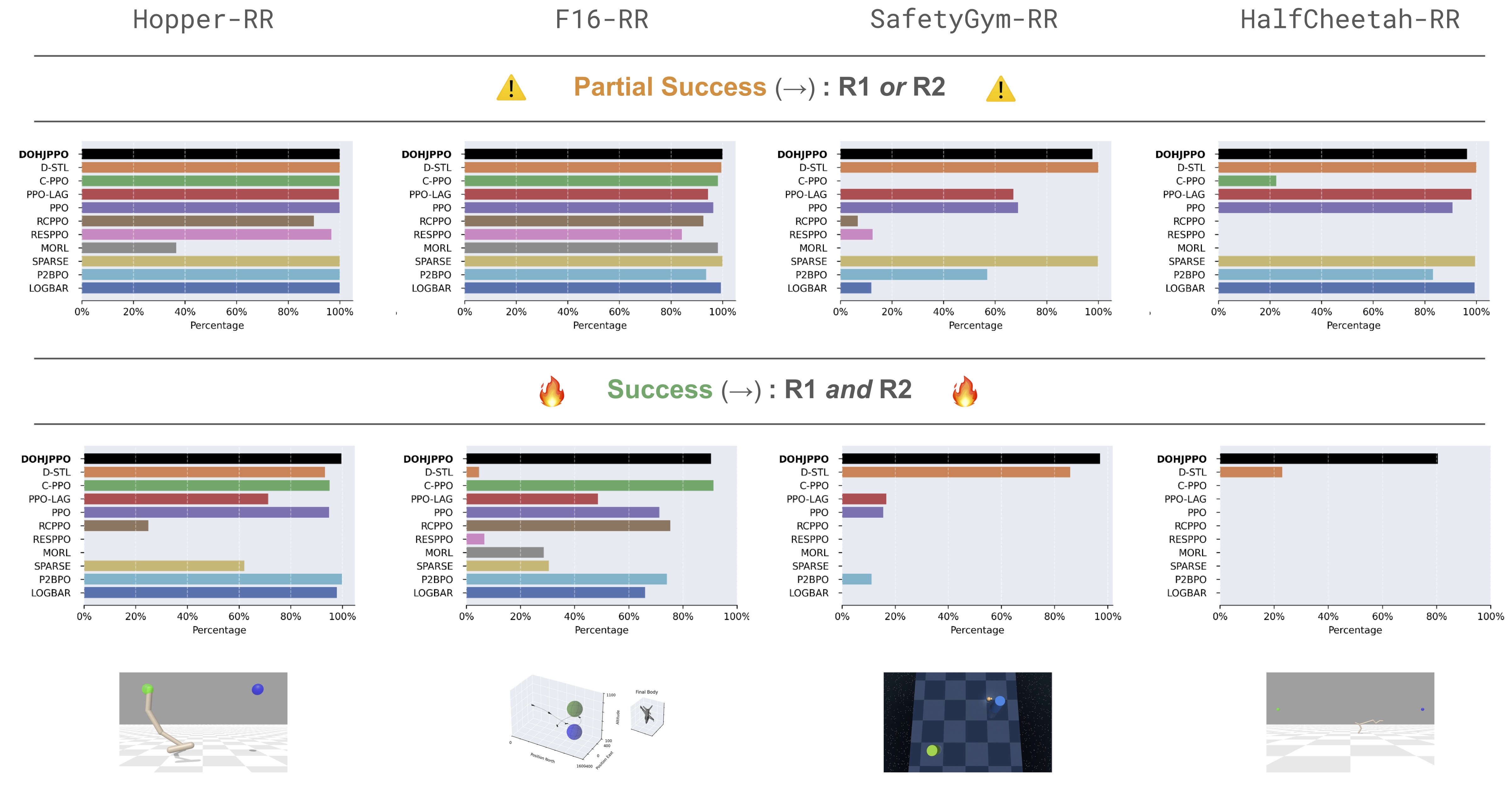
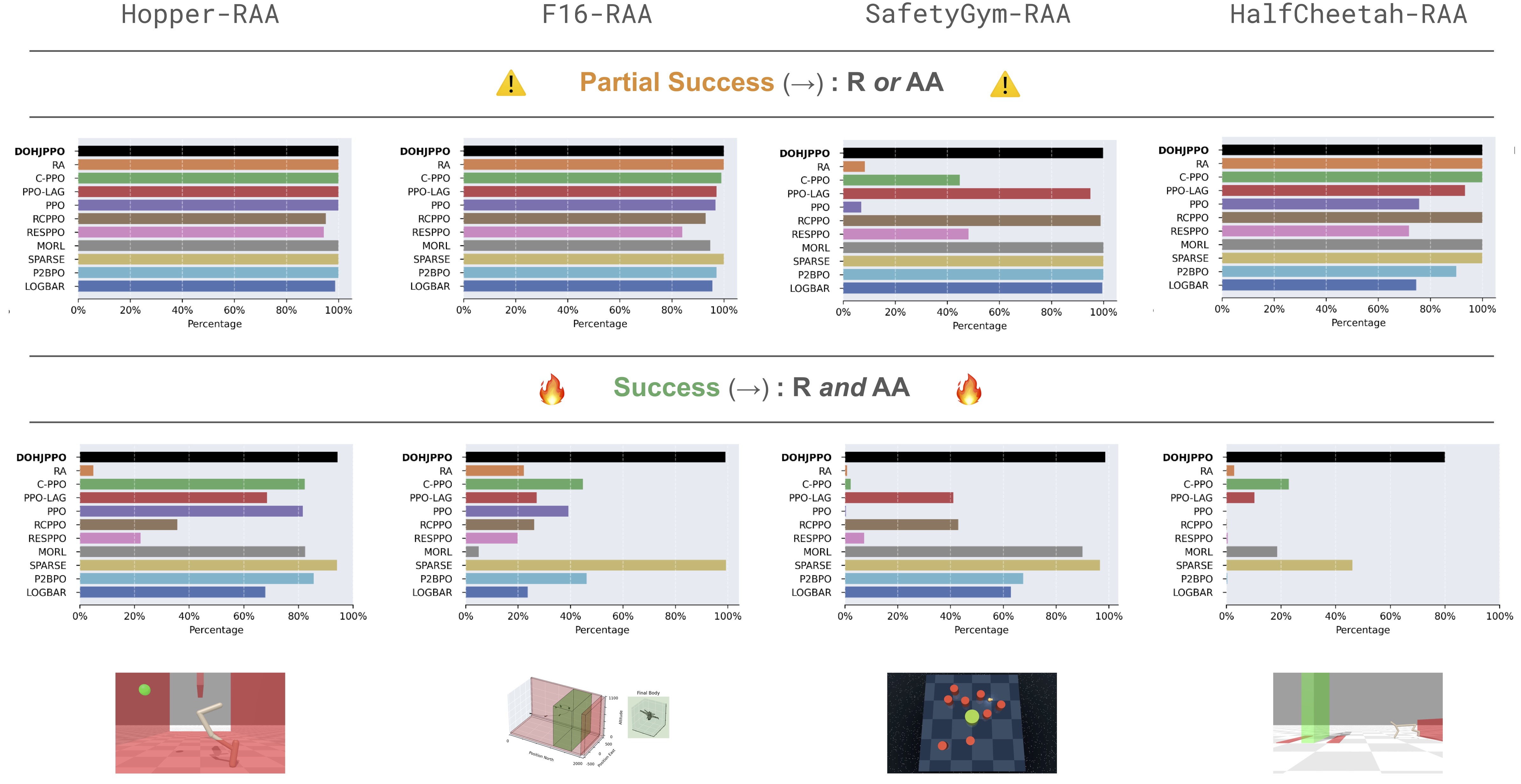
DOHJ-PPO (black) is amongst top performers in all experiments (\(\rightarrow\)), one of few algos. to work as the env-task gets more complex (\(\rightarrow\)), and the only alg. to excel in both RR and RAA problems. DOHJ-PPO requires little to no tuning due to the nature of the max and mins in the Value definition, unlike augmented-lagrangian approaches which must be iteratively tuned to balance the additive objective.
Future Work
The results derived here are in fact fundamental base cases of a grander algebra. See our recent work on Bellman Value Decomposition for a generalization of these approaches to complex tasks formalized in temporal logic.