Abstract
Real-world tasks involve nuanced combinations of goal and safety specifications. In high dimensions, the challenge is exacerbated: formal automata become cumbersome, and the combination of sparse rewards tends to require laborious tuning. In this work, we consider the innate structure of the Bellman Value as a means to naturally organize the problem for improved automatic performance. Namely, we prove the Value for a complex task defined in temporal logic can be decomposed into a graph of Values, connected by a set of well-known Bellman equations (BEs): the Reach-Avoid BE, the Avoid BE, and a novel type, the Reach-Avoid-Loop BE. To solve the Value and optimal policy, we propose VDPPO, which embeds the decomposed Value graph into a two-layer neural net, bootstrapping the implicit dependencies. We conduct a variety of simulated and hardware experiments to test our method on complex, high-dimensional tasks involving heterogeneous teams and nonlinear dynamics. Ultimately, we find this approach greatly improves performance over existing baselines, balancing safety and liveness automatically.
Context
How do you teach a robot or agent to perform a complex task? Given a state \(x\) and time \(t\), let a reward \(\textcolor{4D72B0}{r}\) and penalty \(\textcolor{cc6566}{q}\) be defined for the given task. Traditional reinforcement learning solves the optimal Value \(V^*\) for the discounted-sum,
where \(\alpha := (a_1, a_2, ... ) \) denotes an action-sequence, and \(\xi_x^\alpha(t)\), the trajectory. Thus, \(V^*\) gives a high-score and the actions to achieve it; if \(\textcolor{4D72B0}{r}\) and \(\textcolor{cc6566}{q}\) are defined well, an agent will learn to perform the task.
But in this framework, "defined well" is a task itself. For example,
- The dynamics may bias learning such that a nontrivial \(\lambda\) is needed for both performant and safe behavior. In practice, engineers iteratively tune, which is both laborious and costly for deployment.
- The agent might "hack" the high-score by offsetting a penalty with a larger reward. The sum is sensitive to agentic misalignment; poor surrogates can yield unintended and dangerous behavior.
For these reasons, we propose learning with a different Value defined by the task logic itself to structure and simplify the problem.
Logical Task Values
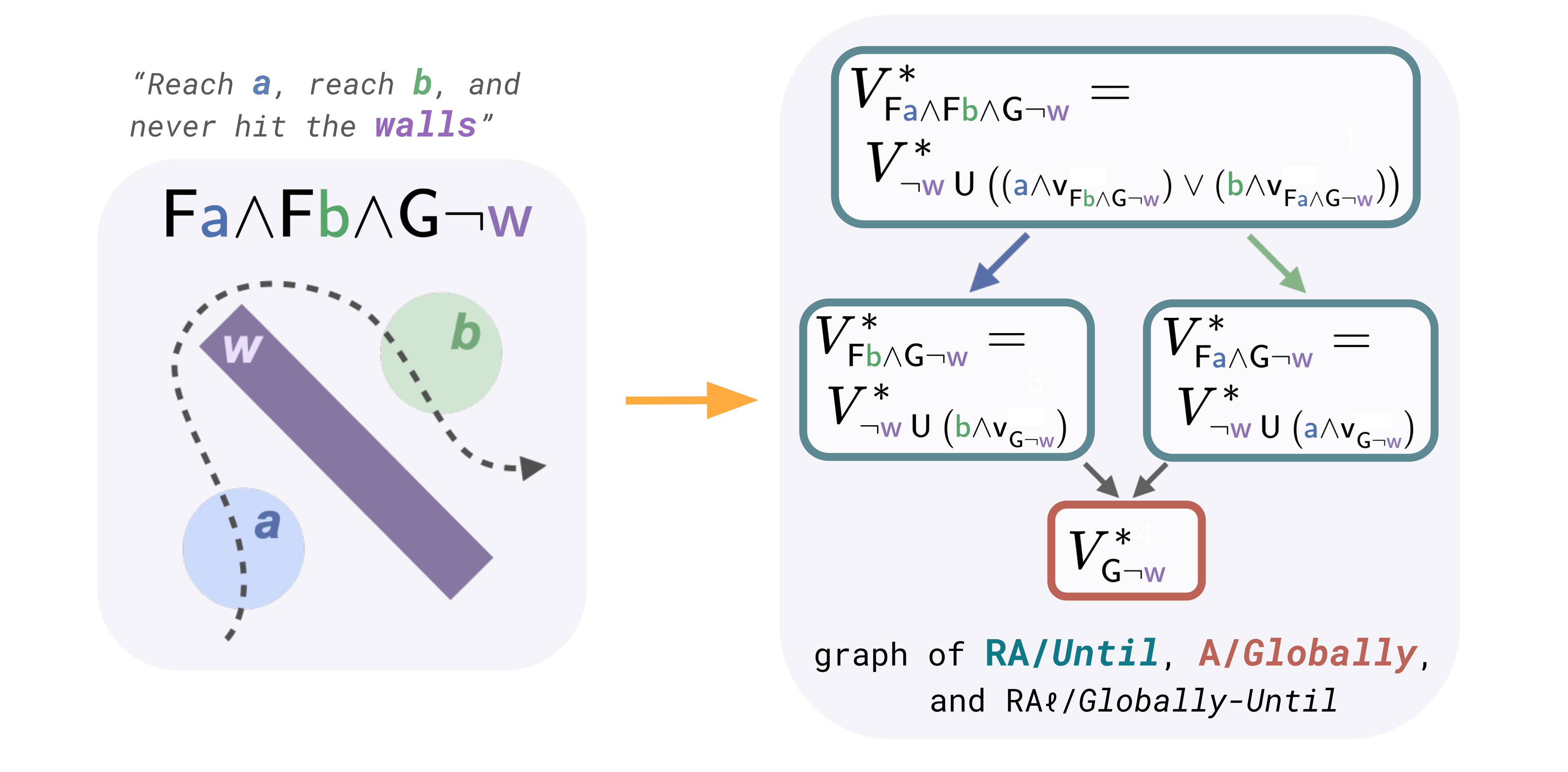
Consider a task written in temporal logic (TL): operators for standard (eg. AND \(\wedge\), OR \(\vee\), NOT \(\neg\)) and temporal (eg. eventually \(\mathsf{F}\), always \(\mathsf{G}\), until \(\mathsf{U}\)) logic can be composed to define complex specifications.
For example, "reach \(\mathsf{\textcolor{#4D72B0}{a}}\) and reach \(\mathsf{\textcolor{#55A868}{b}}\) and never hit the \(\mathsf{\textcolor{#8C72B3}{walls}}\)" can be written \(\mathsf{p}:=\mathsf{F} \mathsf{\textcolor{#4D72B0}{a}} \land \mathsf{F} \mathsf{\textcolor{#55A868}{b}} \land \mathsf{G}\lnot \mathsf{\textcolor{#8C72B3}{w}}\).
The satisfaction of a task can be scored with a real-valued function \(\rho\) called the robustness metric, defined constructively (). For the given example, note \(\rho[\mathsf{F} \mathsf{\textcolor{#4D72B0}{a}} \land \mathsf{F} \mathsf{\textcolor{#55A868}{b}} \land \mathsf{G}\lnot \mathsf{\textcolor{#8C72B3}{w}}](\xi_x^\alpha) = \min \{ \max_{t} \textcolor{#4D72B0}{a}(\xi_x^\alpha(t)), \max_{t'} \textcolor{#55A868}{b}(\xi_x^\alpha(t')), \min_{t''} -\textcolor{#8C72B3}{w}(\xi_x^\alpha(t'')) \}\).

In this setting, let the optimal Value for general task logic \(\mathsf{p}\) be defined as,
This definition is not additive: it strictly integrates the logical structure and thus is robust to tuning and misalignment (see paper for more discussion).
This definition generalizes several well-studied problems in Hamilton-Jacobi reachability (HJR):

This fact is crucial, as each of the above "atomic" task Values has a well-studied Bellman equation and is thus simple to solve. While this perspective is general, deriving a Bellman equation for any \(V^*[\mathsf{p}]\) is more difficult than in the traditional setting, obstructing learning even in simple systems. Here in lies the challenge in this framework and the contribution of our work.
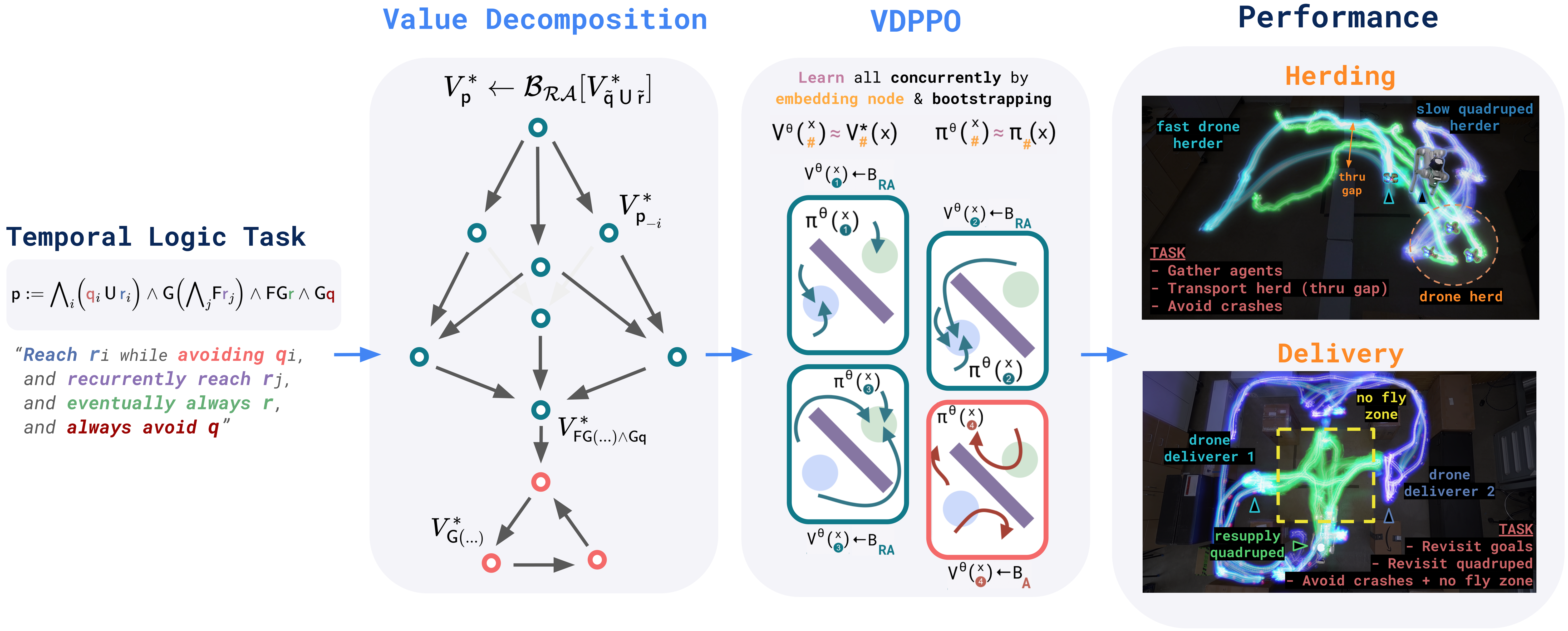
Value Decomposition
To derive Bellman equations for general logic, we introduce Value Decomposition Rules (VDR), a set of algebraic rules for decomposing a TL Value. Here, \(\mathsf{\textcolor{#FFAB40}{v}}[\mathsf{p}]\) is the predicate for \(V^*[\mathsf{p}]\) such that \(\rho[\mathsf{\textcolor{#FFAB40}{v}}[\mathsf{p}]](\xi_{x}, t) := V^*[\mathsf{p}](\xi_{x}(t))\), and is thus satisfied at the zero-level set.

In combination with logical manipulation, the VDR transform a general Value into well-studied Values with known Bellman equations, corresponding to pieces of the total logic.
Here, we show how to wield the VDR to synthesize the decomposed Value graph (DVG).
To scale this process, we wrote valtr to automatically manipulate a given specification and recursively apply the VDR to generate the DVG and its Bellman equations. Examples below (try your own logic).
%%{init: {"theme":"base","htmlLabels":true,"flowchart":{"padding":8,"diagramPadding":48},"themeVariables":{"background":"#FFFFFF00","fontFamily":"JetBrains Mono, Roboto Mono, Menlo, Consolas, monospace","edgeLabelBackground":"#FFFFFF","lineColor":"#2c3e50","defaultLinkColor":"#2c3e50"},"themeCSS":".edgeLabel rect { fill: #FFFFFF !important; stroke: #2c3e50 !important; stroke-width: 1px !important; rx: 999px; ry: 999px; } .edgeLabel span, .edgeLabel p { background: transparent !important; } .edgeLabel foreignObject { background: transparent !important; } .labelBkg { fill: #FFFFFF !important; } .flowchart-link, .edgePath path, .edge-thickness-normal, .edge-thickness-thick { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: none !important; } .arrowheadPath { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: #2c3e50 !important; } svg { background-color: transparent; }"}%%
flowchart LR
n0@{ shape: rectangle, label: "'a'" }
n1@{ shape: rectangle, label: "'b'" }
n2@{ shape: rectangle, label: "'w'" }
n3@{ shape: rounded, label: "neg." }
n4@{ shape: rounded, label: "avoid Value (n.4)" }
n5@{ shape: rounded, label: "min" }
n6@{ shape: rounded, label: "reach-avoid Value (n.6)" }
n7@{ shape: rounded, label: "min" }
n8@{ shape: rounded, label: "min" }
n9@{ shape: rounded, label: "reach-avoid Value (n.9)" }
n10@{ shape: rounded, label: "min" }
n11@{ shape: rounded, label: "max" }
n12@{ shape: rounded, label: "reach-avoid Value (n.12)" }
n3 ==> n2
n4 ==> n3
n5 ==> n1
n5 ==> n4
n6 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n5
n6 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n3
n7 ==> n0
n7 ==> n6
n8 ==> n0
n8 ==> n4
n9 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n8
n9 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n3
n10 ==> n1
n10 ==> n9
n11 ==> n7
n11 ==> n10
n12 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n11
n12 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n3
class n0 var;
class n1 var;
class n2 var;
class n3 negate;
class n4 avoid;
class n5 min;
class n6 reachavoid;
class n7 min;
class n8 min;
class n9 reachavoid;
class n10 min;
class n11 max;
class n12 reachavoid;
classDef const fill:#95a5a688,stroke:#95a5a6,color:#111111,stroke-width:5px,font-size:25px;
classDef var fill:#FFFFFF88,stroke:#FFFFFF,color:#111111,stroke-width:5px,font-size:20px;
classDef min fill:#E9E0C488,stroke:#E9E0C4,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef max fill:#D8CCA388,stroke:#D8CCA3,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef reachavoid fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef avoid fill:#CD3A3A88,stroke:#CD3A3A,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef reach fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef gu fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:25px;
classDef gumin fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:15px;
classDef negate fill:#B98EC888,stroke:#B98EC8,color:#FFFFFF,stroke-width:5px,font-size:15px;
style n12 stroke:#1B5B93,stroke-width:8px; %%{init: {"theme":"base","htmlLabels":true,"flowchart":{"padding":8,"diagramPadding":48},"themeVariables":{"background":"#FFFFFF00","fontFamily":"JetBrains Mono, Roboto Mono, Menlo, Consolas, monospace","edgeLabelBackground":"#FFFFFF","lineColor":"#2c3e50","defaultLinkColor":"#2c3e50"},"themeCSS":".edgeLabel rect { fill: #FFFFFF !important; stroke: #2c3e50 !important; stroke-width: 1px !important; rx: 999px; ry: 999px; } .edgeLabel span, .edgeLabel p { background: transparent !important; } .edgeLabel foreignObject { background: transparent !important; } .labelBkg { fill: #FFFFFF !important; } .flowchart-link, .edgePath path, .edge-thickness-normal, .edge-thickness-thick { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: none !important; } .arrowheadPath { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: #2c3e50 !important; } svg { background-color: transparent; }"}%%
flowchart TD
n0@{ shape: rectangle, label: "'a'" }
n1@{ shape: rectangle, label: "'b'" }
n2@{ shape: rectangle, label: "'key'" }
n3@{ shape: rectangle, label: "'wall'" }
n4@{ shape: rounded, label: "neg." }
n5@{ shape: rounded, label: "avoid Value (n.5)" }
n6@{ shape: rounded, label: "min" }
n7@{ shape: rectangle, label: "'door'" }
n8@{ shape: rounded, label: "neg." }
n9@{ shape: rounded, label: "min" }
n10@{ shape: rounded, label: "reach-avoid Value (n.10)" }
n11@{ shape: rounded, label: "min" }
n12@{ shape: rounded, label: "min" }
n13@{ shape: rounded, label: "reach-avoid Value (n.13)" }
n14@{ shape: rounded, label: "min" }
n15@{ shape: rounded, label: "max" }
n16@{ shape: rounded, label: "reach-avoid Value (n.16)" }
n17@{ shape: rounded, label: "min" }
n18@{ shape: rounded, label: "min" }
n19@{ shape: rounded, label: "min" }
n20@{ shape: rounded, label: "reach-avoid Value (n.20)" }
n21@{ shape: rounded, label: "min" }
n22@{ shape: rounded, label: "max" }
n23@{ shape: rounded, label: "reach-avoid Value (n.23)" }
n24@{ shape: rounded, label: "min" }
n25@{ shape: rounded, label: "min" }
n26@{ shape: rounded, label: "min" }
n27@{ shape: rounded, label: "max" }
n28@{ shape: rounded, label: "reach-avoid Value (n.28)" }
n29@{ shape: rounded, label: "min" }
n30@{ shape: rounded, label: "max" }
n31@{ shape: rounded, label: "reach-avoid Value (n.31)" }
n4 ==> n3
n5 ==> n4
n6 ==> n2
n6 ==> n5
n8 ==> n7
n9 ==> n4
n9 ==> n8
n10 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n6
n10 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n9
n11 ==> n1
n11 ==> n10
n12 ==> n1
n12 ==> n5
n13 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n12
n13 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n4
n14 ==> n2
n14 ==> n13
n15 ==> n11
n15 ==> n14
n16 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n15
n16 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n9
n17 ==> n0
n17 ==> n16
n18 ==> n0
n18 ==> n10
n19 ==> n0
n19 ==> n5
n20 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n19
n20 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n4
n21 ==> n2
n21 ==> n20
n22 ==> n18
n22 ==> n21
n23 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n22
n23 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n9
n24 ==> n1
n24 ==> n23
n25 ==> n0
n25 ==> n13
n26 ==> n1
n26 ==> n20
n27 ==> n25
n27 ==> n26
n28 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n27
n28 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n4
n29 ==> n2
n29 ==> n28
n30 ==> n17
n30 ==> n24
n30 ==> n29
n31 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n30
n31 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n9
class n0 var;
class n1 var;
class n2 var;
class n3 var;
class n4 negate;
class n5 avoid;
class n6 min;
class n7 var;
class n8 negate;
class n9 min;
class n10 reachavoid;
class n11 min;
class n12 min;
class n13 reachavoid;
class n14 min;
class n15 max;
class n16 reachavoid;
class n17 min;
class n18 min;
class n19 min;
class n20 reachavoid;
class n21 min;
class n22 max;
class n23 reachavoid;
class n24 min;
class n25 min;
class n26 min;
class n27 max;
class n28 reachavoid;
class n29 min;
class n30 max;
class n31 reachavoid;
classDef const fill:#95a5a688,stroke:#95a5a6,color:#111111,stroke-width:5px,font-size:25px;
classDef var fill:#FFFFFF88,stroke:#FFFFFF,color:#111111,stroke-width:5px,font-size:20px;
classDef min fill:#E9E0C488,stroke:#E9E0C4,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef max fill:#D8CCA388,stroke:#D8CCA3,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef reachavoid fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef avoid fill:#CD3A3A88,stroke:#CD3A3A,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef reach fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef gu fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:25px;
classDef gumin fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:15px;
classDef negate fill:#B98EC888,stroke:#B98EC8,color:#FFFFFF,stroke-width:5px,font-size:15px;
style n31 stroke:#1B5B93,stroke-width:8px; %%{init: {"theme":"base","htmlLabels":true,"flowchart":{"padding":8,"diagramPadding":48},"themeVariables":{"background":"#FFFFFF00","fontFamily":"JetBrains Mono, Roboto Mono, Menlo, Consolas, monospace","edgeLabelBackground":"#FFFFFF","lineColor":"#2c3e50","defaultLinkColor":"#2c3e50"},"themeCSS":".edgeLabel rect { fill: #FFFFFF !important; stroke: #2c3e50 !important; stroke-width: 1px !important; rx: 999px; ry: 999px; } .edgeLabel span, .edgeLabel p { background: transparent !important; } .edgeLabel foreignObject { background: transparent !important; } .labelBkg { fill: #FFFFFF !important; } .flowchart-link, .edgePath path, .edge-thickness-normal, .edge-thickness-thick { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: none !important; } .arrowheadPath { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: #2c3e50 !important; } svg { background-color: transparent; }"}%%
flowchart LR
n0@{ shape: rectangle, label: "'gear'" }
n1@{ shape: rectangle, label: "'site_a'" }
n2@{ shape: rectangle, label: "'worksite'" }
n3@{ shape: rounded, label: "avoid Value (n.3)" }
n4@{ shape: rounded, label: "min" }
n5@{ shape: rounded, label: "reach-avoid-loop Value (n.5)" }
n6@{ shape: rectangle, label: "'battery'" }
n7@{ shape: rounded, label: "min" }
n8@{ shape: rounded, label: "reach-avoid-loop Value (n.8)" }
n9@{ shape: rounded, label: "min-loop" }
n10@{ shape: rounded, label: "reach Value (n.10)" }
n11@{ shape: rounded, label: "min" }
n12@{ shape: rounded, label: "neg." }
n13@{ shape: rounded, label: "reach-avoid Value (n.13)" }
n3 ==> n2
n4 ==> n1
n4 ==> n3
n5 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n4
n5 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n2
n7 ==> n3
n7 ==> n6
n8 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n7
n8 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n2
n9 ==> n5
n9 ==> n8
n10 ==> n9
n11 ==> n0
n11 ==> n10
n12 ==> n2
n13 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n11
n13 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n12
class n0 var;
class n1 var;
class n2 var;
class n3 avoid;
class n4 min;
class n5 gu;
class n6 var;
class n7 min;
class n8 gu;
class n9 gumin;
class n10 reach;
class n11 min;
class n12 negate;
class n13 reachavoid;
classDef const fill:#95a5a688,stroke:#95a5a6,color:#111111,stroke-width:5px,font-size:25px;
classDef var fill:#FFFFFF88,stroke:#FFFFFF,color:#111111,stroke-width:5px,font-size:20px;
classDef min fill:#E9E0C488,stroke:#E9E0C4,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef max fill:#D8CCA388,stroke:#D8CCA3,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef reachavoid fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef avoid fill:#CD3A3A88,stroke:#CD3A3A,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef reach fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef gu fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:25px;
classDef gumin fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:15px;
classDef negate fill:#B98EC888,stroke:#B98EC8,color:#FFFFFF,stroke-width:5px,font-size:15px;
style n13 stroke:#1B5B93,stroke-width:8px; %%{init: {"theme":"base","htmlLabels":true,"flowchart":{"padding":8,"diagramPadding":48},"themeVariables":{"background":"#FFFFFF00","fontFamily":"JetBrains Mono, Roboto Mono, Menlo, Consolas, monospace","edgeLabelBackground":"#FFFFFF","lineColor":"#2c3e50","defaultLinkColor":"#2c3e50"},"themeCSS":".edgeLabel rect { fill: #FFFFFF !important; stroke: #2c3e50 !important; stroke-width: 1px !important; rx: 999px; ry: 999px; } .edgeLabel span, .edgeLabel p { background: transparent !important; } .edgeLabel foreignObject { background: transparent !important; } .labelBkg { fill: #FFFFFF !important; } .flowchart-link, .edgePath path, .edge-thickness-normal, .edge-thickness-thick { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: none !important; } .arrowheadPath { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: #2c3e50 !important; } svg { background-color: transparent; }"}%%
flowchart LR
n0@{ shape: rectangle, label: "'r0'" }
n1@{ shape: rectangle, label: "'r1'" }
n2@{ shape: rounded, label: "reach Value (n.2)" }
n3@{ shape: rounded, label: "min" }
n4@{ shape: rectangle, label: "'herded'" }
n5@{ shape: rounded, label: "avoid Value (n.5)" }
n6@{ shape: rectangle, label: "'collide'" }
n7@{ shape: rounded, label: "neg." }
n8@{ shape: rounded, label: "reach-avoid Value (n.8)" }
n9@{ shape: rounded, label: "min" }
n10@{ shape: rounded, label: "reach-avoid Value (n.10)" }
n2 ==> n1
n3 ==> n0
n3 ==> n2
n5 ==> n4
n7 ==> n6
n8 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n5
n8 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n7
n9 ==> n3
n9 ==> n8
n10 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n9
n10 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n7
class n0 var;
class n1 var;
class n2 reach;
class n3 min;
class n4 var;
class n5 avoid;
class n6 var;
class n7 negate;
class n8 reachavoid;
class n9 min;
class n10 reachavoid;
classDef const fill:#95a5a688,stroke:#95a5a6,color:#111111,stroke-width:5px,font-size:25px;
classDef var fill:#FFFFFF88,stroke:#FFFFFF,color:#111111,stroke-width:5px,font-size:20px;
classDef min fill:#E9E0C488,stroke:#E9E0C4,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef max fill:#D8CCA388,stroke:#D8CCA3,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef reachavoid fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef avoid fill:#CD3A3A88,stroke:#CD3A3A,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef reach fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef gu fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:25px;
classDef gumin fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:15px;
classDef negate fill:#B98EC888,stroke:#B98EC8,color:#FFFFFF,stroke-width:5px,font-size:15px;
style n10 stroke:#1B5B93,stroke-width:8px; %%{init: {"theme":"base","htmlLabels":true,"flowchart":{"padding":8,"diagramPadding":48},"themeVariables":{"background":"#FFFFFF00","fontFamily":"JetBrains Mono, Roboto Mono, Menlo, Consolas, monospace","edgeLabelBackground":"#FFFFFF","lineColor":"#2c3e50","defaultLinkColor":"#2c3e50"},"themeCSS":".edgeLabel rect { fill: #FFFFFF !important; stroke: #2c3e50 !important; stroke-width: 1px !important; rx: 999px; ry: 999px; } .edgeLabel span, .edgeLabel p { background: transparent !important; } .edgeLabel foreignObject { background: transparent !important; } .labelBkg { fill: #FFFFFF !important; } .flowchart-link, .edgePath path, .edge-thickness-normal, .edge-thickness-thick { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: none !important; } .arrowheadPath { stroke: #2c3e50 !important; stroke-width: 2.25px !important; fill: #2c3e50 !important; } svg { background-color: transparent; }"}%%
flowchart LR
n0@{ shape: rectangle, label: "'air_crash'" }
n1@{ shape: rounded, label: "neg." }
n2@{ shape: rectangle, label: "'obstacle'" }
n3@{ shape: rounded, label: "neg." }
n4@{ shape: rectangle, label: "'no_fly_zone'" }
n5@{ shape: rounded, label: "neg." }
n6@{ shape: rounded, label: "min" }
n7@{ shape: rounded, label: "avoid Value (n.7)" }
n8@{ shape: rectangle, label: "'drop1'" }
n9@{ shape: rounded, label: "min" }
n10@{ shape: rounded, label: "reach-avoid-loop Value (n.10)" }
n11@{ shape: rectangle, label: "'drop2'" }
n12@{ shape: rounded, label: "min" }
n13@{ shape: rounded, label: "reach-avoid-loop Value (n.13)" }
n14@{ shape: rectangle, label: "'resupply1'" }
n15@{ shape: rounded, label: "min" }
n16@{ shape: rounded, label: "reach-avoid-loop Value (n.16)" }
n17@{ shape: rectangle, label: "'resupply2'" }
n18@{ shape: rounded, label: "min" }
n19@{ shape: rounded, label: "reach-avoid-loop Value (n.19)" }
n20@{ shape: rounded, label: "min-loop" }
n1 ==> n0
n3 ==> n2
n5 ==> n4
n6 ==> n1
n6 ==> n3
n6 ==> n5
n7 ==> n6
n9 ==> n7
n9 ==> n8
n10 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n9
n10 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n6
n12 ==> n7
n12 ==> n11
n13 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n12
n13 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n6
n15 ==> n7
n15 ==> n14
n16 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n15
n16 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n6
n18 ==> n7
n18 ==> n17
n19 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#FFFFFFF5;border:1px solid #86AECBF5;color:#4698E0 !important;opacity:1;">reach</span>| n18
n19 ==>|<span style="display:inline-block;padding:2px 6px;border-radius:999px;background:#F7DDDDF5;border:1px solid #D99898F5;color:#D95454 !important;opacity:1;">avoid</span>| n6
n20 ==> n10
n20 ==> n13
n20 ==> n16
n20 ==> n19
class n0 var;
class n1 negate;
class n2 var;
class n3 negate;
class n4 var;
class n5 negate;
class n6 min;
class n7 avoid;
class n8 var;
class n9 min;
class n10 gu;
class n11 var;
class n12 min;
class n13 gu;
class n14 var;
class n15 min;
class n16 gu;
class n17 var;
class n18 min;
class n19 gu;
class n20 gumin;
classDef const fill:#95a5a688,stroke:#95a5a6,color:#111111,stroke-width:5px,font-size:25px;
classDef var fill:#FFFFFF88,stroke:#FFFFFF,color:#111111,stroke-width:5px,font-size:20px;
classDef min fill:#E9E0C488,stroke:#E9E0C4,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef max fill:#D8CCA388,stroke:#D8CCA3,color:#FFFFFF,stroke-width:5px,font-size:15px;
classDef reachavoid fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef avoid fill:#CD3A3A88,stroke:#CD3A3A,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef reach fill:#1B5B9388,stroke:#1B5B93,color:#FFFFFF,stroke-width:5px,font-size:25px;
classDef gu fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:25px;
classDef gumin fill:#3AA65588,stroke:#3AA655,color:#111111,stroke-width:5px,font-size:15px;
classDef negate fill:#B98EC888,stroke:#B98EC8,color:#FFFFFF,stroke-width:5px,font-size:15px;
style n20 stroke:#3AA655,stroke-width:8px; VDPPO

To solve the DVG, we introduce Value Decomposition PPO (VDPPO), a minimal extension of PPO to leverage the structure of the DVG.
VDPPO involves a single actor and critic that embed the DVG with a one-hot vector. By distributing rollouts across graph nodes, the algorithm learns all Values and their policies concurrently. To do so, the critic is updated with the Bellman equation corresponding to the node type, where dependent Values are bootstrapped. This avoids the combinatorial explosion associated with representing each independently (as in the TSP or automata), and allows the model to leverage shared "skills" for different sub-tasks. Online, the policy is executed from the root node and switches down the graph according to the satisfaction of the predicates.
Empirically, we find that VDPPO outperforms baselines that do not leverage the DVG structure. Notably, the performance gap grows with the complexity of the task, suggesting the importance of leveraging the logical structure.
Robotics
To test the framework in the real world, we deployed VDPPO on two robotic tasks: herding and delivery. Both tasks involve complex logic with heterogeneous teams, and require learning a variety of sub-tasks (eg. navigation, coordination) to succeed.
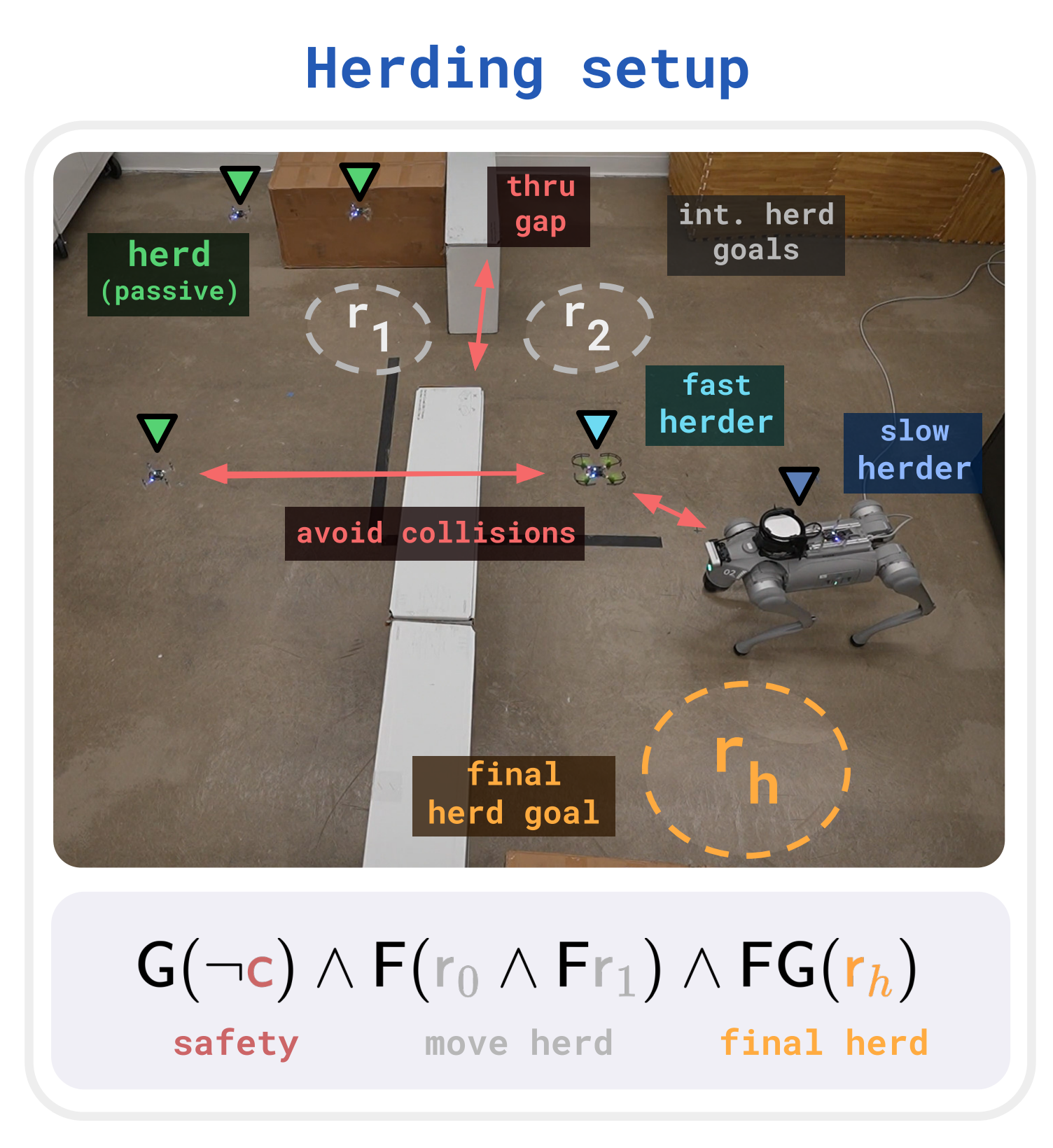
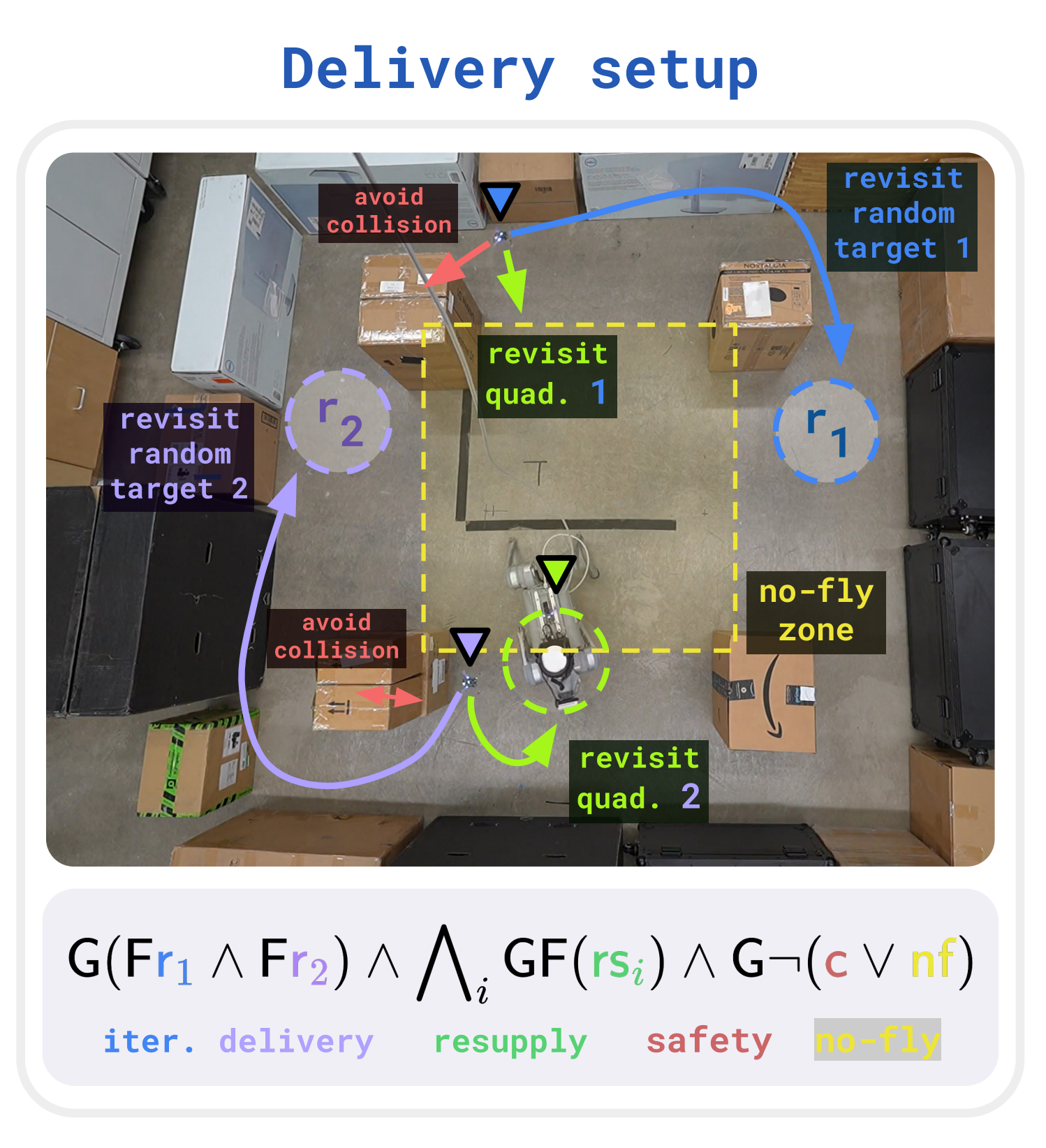
In both experiments, we find that VDPPO yields highly performant policies that achieve the task rapidly and safely that automatically divide the labor. By leveraging the DVG, the actor and critic here need only two-layer MLPs (512 parameters) to yield strong behavior, training in less than an hour on a single 2080 GeForce GPU, demonstrating the efficiency of the framework.
These results demonstrate the promise of the framework for real-world robotics, where complex tasks and safety are paramount. By leveraging the logical structure of the task, we can simplify reward engineering and RL for real-world deployment. See the paper for more discussion and results.
Future Work
While this work offers a new framework for learning complex tasks, as an initial effort, there are some limitations and open questions which we outline. (1) The DVG for any-order achievement has TSP-like exponential growth; for large graphs, pruning or curriculums may be necessary. (2) The decompositions are not equivalent in expectation; a policy gradient is still derivable and functional, but further analysis is needed. (3) The proposed Value does not consider running-cost, however, this might be introduced via epigraph forms. See the paper for more discussion. See our ICLR 2026 work on dual-objective Values (a base case for algebraic decompositions) for analysis of these questions in the simpler setting.